
Natural language processing (NLP) has made significant strides in recent years with the introduction of the Transformer model. The Transformer model, first introduced in a 2017 paper by Vaswani et al., has become the backbone for many of the state-of-the-art NLP models including the widely popular ChatGPT, a language model trained by OpenAI. In this article, we will explore what the Transformer model is, how it works, and why it has become a game-changer in NLP.
What is the Transformer model?
The Transformer model is a type of neural network architecture that was specifically designed for sequence-to-sequence learning tasks, such as language translation or text summarization. Unlike previous models, which relied heavily on recurrent neural networks (RNNs), the Transformer model uses only self-attention mechanisms, which allows it to capture global dependencies in the input sequence more efficiently.
How does it work?
The Transformer model is composed of two main parts: the encoder and the decoder. The encoder takes in an input sequence and converts it into a sequence of hidden representations, where each representation corresponds to a specific position in the input sequence. The decoder then takes in these hidden representations and generates an output sequence, which can be a translation or a summary of the input sequence.

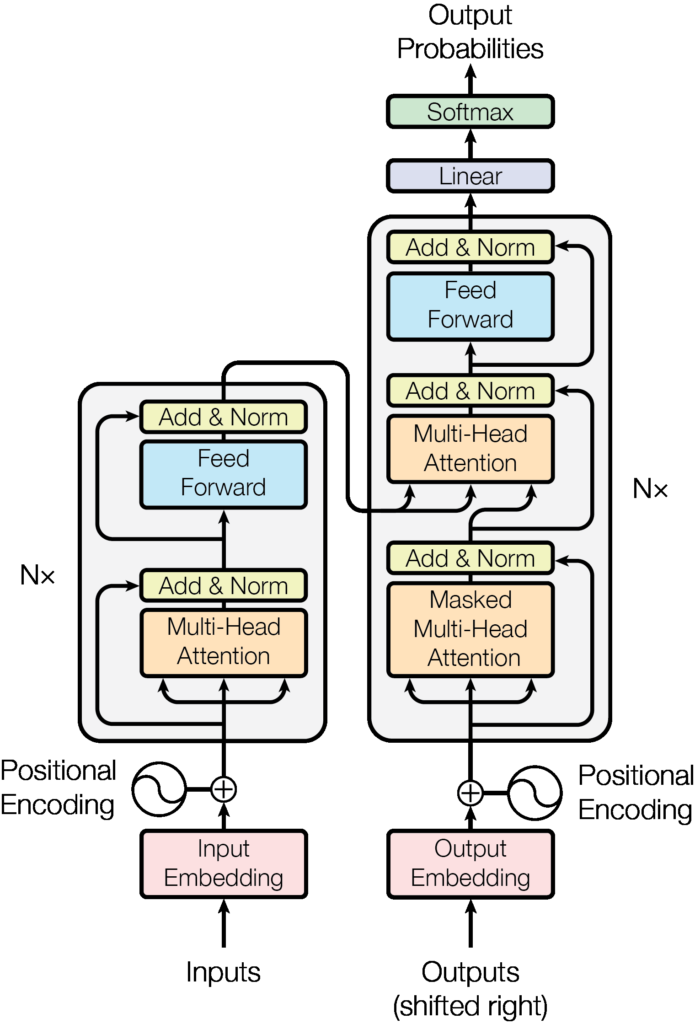
The key innovation of the Transformer model lies in its use of self-attention mechanisms, which allow it to attend to all positions in the input sequence to compute a representation for each position. This is in contrast to RNNs, which process the input sequence sequentially, and therefore can struggle with long-range dependencies. By attending to all positions simultaneously, the Transformer model can capture global dependencies more efficiently, which leads to improved performance on sequence-to-sequence learning tasks.
Why is it a game-changer in NLP?
The Transformer model has revolutionized NLP in several ways. First, it has led to significant improvements in performance on a wide range of NLP tasks, such as machine translation, text summarization, and language modeling. This is due to its ability to capture global dependencies in the input sequence more efficiently than previous models.
Second, the Transformer model has made it possible to train much larger language models, such as the GPT-3 model, which has 175 billion parameters. This has allowed for the development of language models that can generate human-like responses to text prompts, such as ChatGPT.


Read the official research paper on the Transformer Model here